
Important Disclaimer – YOU MUST READ FIRST!
Portions of this article contain source code from the Windows Research Kernel. This code is the intellectual property of Microsoft Corporation. I am using this code under special license in this post under these grounds of the license agreement:
You may distribute snippets of this software in research papers, books or
other teaching materials, or publish snippets of the software on websites
or on-line community forums that are intended for teaching and research.
In addition to the above, the agreement also states that no more than 50 lines “per snippet” of source code can be displayed, to which this article complies with. Lastly, it cannot be used commercially or “reverse-engineered” to be used towards other projects. My usage of this code is intended for academic research, educational, and non-commercial purposes only to contribute to the field of Malware Research. This article is not intended to nor am I attempting to reverse engineer the Windows operating system in an attempt to create a similar product or derivatives of such. This blog earns no money and is not a commercial endeavor; it is intended for teaching and research (hence the name).
Introduction
As a Windows Malware Analyst, I am running sample files all day every day. I open more executables than most Windows users do in a day and one thing I’ve found that’s pretty common is file corruption. Error messages such as “This is not a valid Win32 file,” “This file is not compatible with the operating system version. You may be trying to run a 64 bit file on a 32 bit system” etc… Those messages are not verbatim, but you get the idea. I see a surprisingly large number of these messages.
Some files will run on Windows XP and not on Windows 7. Some will run on Windows 7 but not Windows 10, some will not run on any version of Windows that I have, yet they parse just fine in PE parsing tools like PE Studio. Other files with cause a program like PE Studio or PEInfo to crash or malfunction, but will load just fine on Windows and proceed to run malware.
Why? What is going on here?
The Question
What types of obstructions and anomalies in the PE file can make the Windows Portable Executable Image Loader and other PE parsing programs fail to load the file or display an error message?
This is a question that I’ve sought to answer for several months now and every week I come closer to the answer(s). That’s right, there are many answers. I am still far away from the conclusion to this investigation, however, I am going to summarize my research, findings, and thoughts into this blog post and proceed from there.
Why is this important for Malware Analysis?
The answer to this question is useful for malware analysis for two main reasons:
- If the file will not load, it cannot be dynamically analyzed, thus removing half of the analysis capability at an analysts disposal, leaving only static analysis
- It will allow the analyst to determine if the file will not load on specified systems or in specified environments, or not load at all. If a file will not load at all on any system, it is not malware because it cannot run and perform malicious activity*
*Note: This excludes malware which is used as code libraries, exporting symbols to other processes.
The Purpose of a Portable Executable File
In order to understand more about the file format, let’s first look at its purpose in general. Go and Download a hex editor such as HxD or 010 Editor, my favorite. Open up any .exe file you like by dragging the file onto the editor’s icon. You will see something like the below, except unless you have 010 Editor, you will not see the parsed data structures at the bottom of the screen:
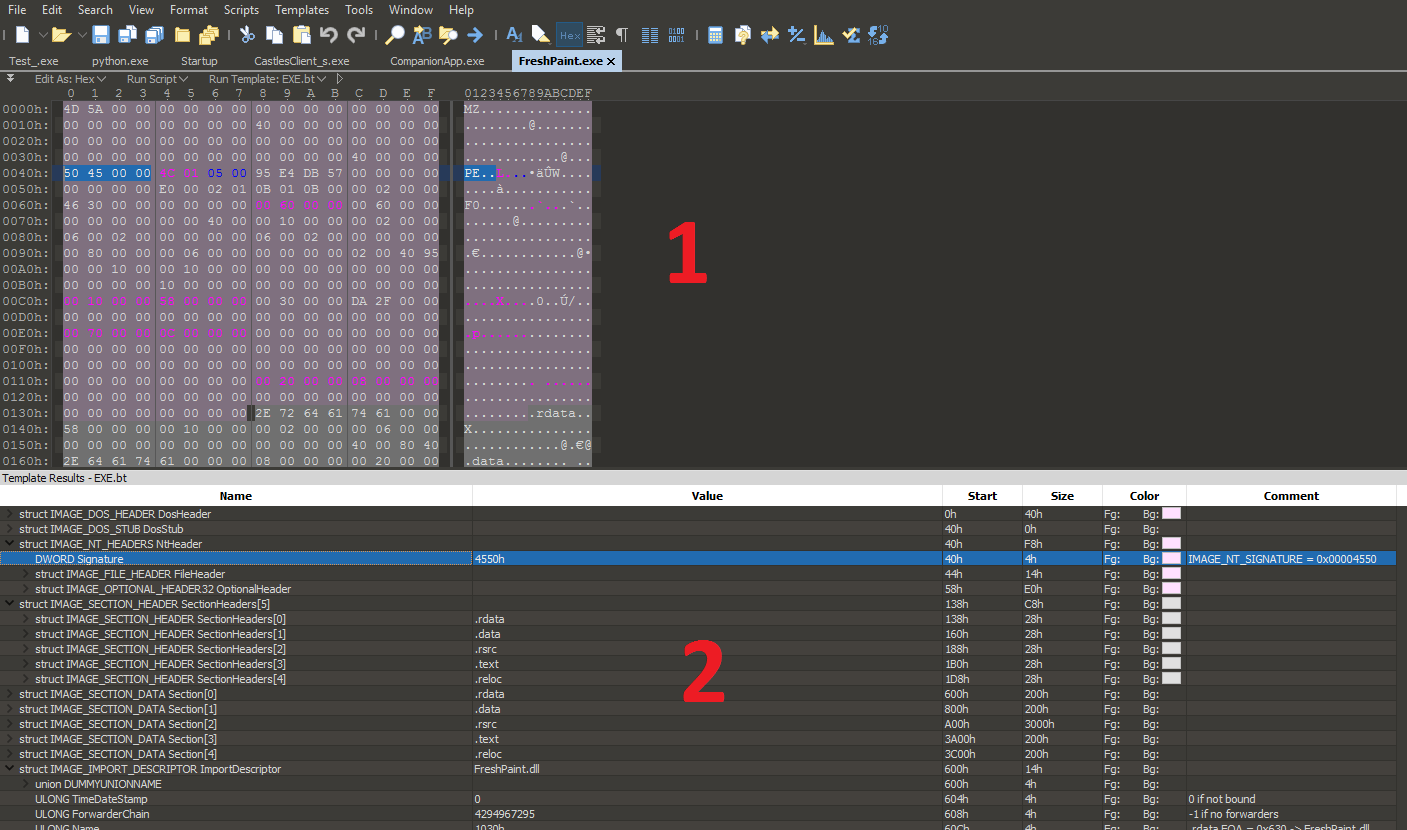
See below walkthrough
At the end of the day, every file on the computer is a series of bytes (ultimately made up of bits). These bytes are either instruction codes for the CPU to follow (so-called “opcodes”) or other information, such as the numbers which represent the characters on this screen, or the background color, or your monitor’s screen resolution, and more. These PE files are no different and the hex editor view highlighted by area #1 in red above, or in your own hex editor shows this fact. The data structures that programmers code in C and C++ ultimately look like this group of bytes pictured above. How does the computer know how to make sense of this seemingly senseless heap of numbers and even more, “execute” them? The answer is by using offsets. One such offset comes in every valid PE and DOS file: the DOS or “MZ” header. This is at “offset 0.” This means “Start at position 0 in the file and then move 0 places.” In other words, the beginning of the MZ header is the first byte in the file. If it is a valid DOS or PE file, the first two bytes will be “4D 5A” which are the bytes which correspond to ASCII characters MZ.
But that offset is boring… Let’s talk about a real offset! Turns out, even though I only showed you the MZ header, it is part of a bigger data structure called the IMAGE_DOS_HEADER, whose very first member is of course the MZ header. The last member is e_lfanew. So let’s digest this:
The IMAGE_DOS_HEADER is a defined data structure. This means that it is consistent – if a PE file is valid it will always have an MZ at the start and there will always be e_lfanew exactly 60 bytes into the file, or 58 bytes past the MZ. In fact, the entire data structure is documented and looks like this:
typedef struct _IMAGE_DOS_HEADER
{
WORD e_magic;
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
LONG e_lfanew;
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
Microsoft defines a WORD as 16 bits, aka 2 bytes. This is consistent with what we just saw because WORD e_magic is the official name of the MZ header, and it was indeed 2 bytes. We then go 4, 6, 8, 10, 12, and keep adding 2 bytes every time we move down by a WORD element above until we get to e_res2, which is an array of 10 WORDS, so 20 bytes. This brings us all the way down into byte 60 (remember, we’re 0-indexed here) as mentioned above: LONG e_lfanew.
Scroll back up to the previous image of the 010 editor, now look at section 2. All a PE file is is a collection of such data structures! In fact, all these data structures are themselves are labels/semantics for a bunch of bytes. We see after the IMAGE_DOS_HEADER comes the IMAGE_DOS_STUB, then IMAGE_NT_HEADERS, IMAGE_SECTION_HEADER, and so on. We can navigate around this file easily by writing a C program and seeking through these data structures since we know the size of each member of each structure.
But that’s not why we’re here. The purpose of that illustration was to lead to the main point:
A Portable Executable File is just a bunch of data structures. But data structures are no good unless they are read and interpreted… By the Windows Portable Executable Image Loader.
What happens when a user double-clicks an .exe file?
Those who work in the software field may already know that a program has a dedicated memory space where it stores such things as global and local variables, static memory, the stack, the heap, and etc… Especially those last 2, they seem to be quite popular in the minds of software developers around the globe. But not that many folks know how that memory space actually gets set up. Of course, several components of the operating system are at play with the setup of memory space, but a major one in this case is the PE Loader.
In reality, the loader does a ton of stuff and going into detail on all of it is out of the scope of this article, but for the purposes of our learning here, the loader:
- Reads the data structures in the PE file that we’ve looked at, as well as others we did not see above
- Makes sense of the information
- Takes the information and locates the library code necessary for the file’s functionality. Programmers and compilers reference operating system APIs and system calls. These functions are stored in DLL files which come with the operating system such as NETAPI32.DLL and WS2_32.DLL. The Loader reads the Import Address Table (IAT) section of the PE data structures, which contains the list of DLLs needed for the PE file, as well as the functions from within those DLLs that are necessary. To do this, it must walk up a series of data structures because those DLLs then also depend on other DLLs, which may depend on others and so on. The loader will blow through all of these structures recursively and resolve the locations in memory at which these files and functions (also called “symbols”) can be found. This is so that when the subject PE needs to call a function, the exact location of the function is plugged in so the instruction pointer can be put there.Without this step in the process, the program would be useless because it would never be able to utilize the Windows API functions which in turn control the machine via the operating system, such as memory allocation, GUI functionality, listening for keystrokes, etc…
- Reserves space for all sections of memory which are to have data placed in them for the program’s functionality such as space for the code section, data section, resource section, read-only data, and more. The loader gets the information for how much memory to allocate for each of these sections from the PE data structures that we’re discussing in this post.
So what we’ve gathered above is that the Loader reads the data structures which make up the PE file to “load” or “map” the bytes from the hard drive or solid-state drive into RAM. Once in RAM, the program is considered “loaded”/active and can be successfully executed by the CPU.
What bad could happen
Already, you are probably painting a picture of what could go wrong to cause a PE file to not correctly load. One of the reasons why this question of mine has been a challenging one to find an answer to is the sheer number of variables. What happens if any of the structs have data that makes no sense? For example, a rogue section value which states that a section is larger than it actually is, or a missing value altogether? What about if the DllCharacteristics member of the IMAGE_OPTIONAL_HEADER has a flipped bit? What if a different Operating System version is specified than the one the machine is intended to run on?
What if we don’t even have an OptionalHeader? After all, it is optional right?
These are all questions that I’ve sought answers to or have spontaneously came up as I examined PE files or attempted to run them and they acted up.
It turns out, the answers are very finnicky and there simply are no hard rules that can be known without a thorough and in-depth study, experimentation, and examination of the file format. The reason for this is not just because of the already-stated number of data structures involved in the file, but also because the Image Loader itself has gone through a series of updates and changes throughout the year. A major theme I’ve noticed though which causes malware problems for people around the globe is that the Image Loader is surprisingly loose in what it will load. Out of all of the data structures you see in the .exe file, only a few are actually needed for the Loader to load the file. This means that malware authors can modify these PE data structures in such a way to make the file either only compatible with certain target machines or potentially crash or confuse analysis tools, yet still be perfectly runnable by the Loader. In an ideal world, at least as far as Malware Analysis is concerned, the Loader would be extremely picky and it would reject any files which didn’t strictly adhere to a uniformed specification. This would force developers to always ship complete PE header info with their malware, making it much easier to analyze.
It turns out, a reverse engineer named Ange Albertini, AKA Corkami, has done very extensive experimentation with the PE file format. Apparently he, too, had these same questions and the way he went about getting them answered is by creating a bunch of different PE files in x86 assembly and then testing them out to see if they would load and how they would load. He then documented his results on this page. I highly recommend reading through Albertini’s findings on that page to get some serious detail about the file format.
However, the format itself is actually only half the battle. In my own research, I’ve taken a slightly different approach and decided, rather than study the data structures and play with the format as Albertini has already, to learn more about the Image Loader itself, including general information about operating system linkers and loaders. A deeper understanding of the loader helps explain some of the mystery and also opens up opportunities for future malware analysis tools.
Loaders are Related to Linkers
It turns out, loaders and linkers actually serve pretty similar purposes. This may seem completely strange at first because when we think of a linker, we think of a program which is at the end of the compilation process which links object files together into a final executable. When we think of a loader, we typically think of a program which reads a file from disk and maps (or “loads”) it into memory. So how are these two utilities even remotely similar?
Well, they are similar because they are both responsible for processes called relocation and symbol resolution.
Relocation
When the Loader is attempting to load a file into memory, it has a default address given to it by the PE header, which is called ImageBase and is a member of the IMAGE_OPTIONAL_HEADER. Sometimes OS cannot load the program into this default address space because another program is already there, for example. At this point, the base address must be adjusted, along with all of the addresses in the program relative to that base address so that the program still functions properly. The information required to do this is stored in the .reloc segment and the process is called relocation.
Symbol Resolution
This is a fancy term for locating all of the external functions which need to be referenced from other library files that are external to the main program. This includes OS API calls as well as any functions or so-called “symbols” from other DLL files. This is a dependency resolution step. For dynamic linking, the loader performs this step. For static linking, it is performed by the linker at link-time/compile-time. The loader recursively checks the Import Address Table (IAT) functions defined in IMAGE_IMPORT_DESCRIPTOR data structures inside the PE file. These structs contain sub-structures called IMAGE_IMPORT_BY_NAME structs which contain the name or “serial number” called the Ordinal, of the function to be imported and from which file it should be imported.
Summary
For our purposes, we can thus summarize that the loader is responsible for reading memory and functional requirements of the program and then ensuring that the memory is available and the necessary external functions are located and ready to be called by our subject program.
Loader Constraints
According to Albertini, the below is the absolute minimum requirement for a PE file to be successfully mapped into memory by the Image Loader:
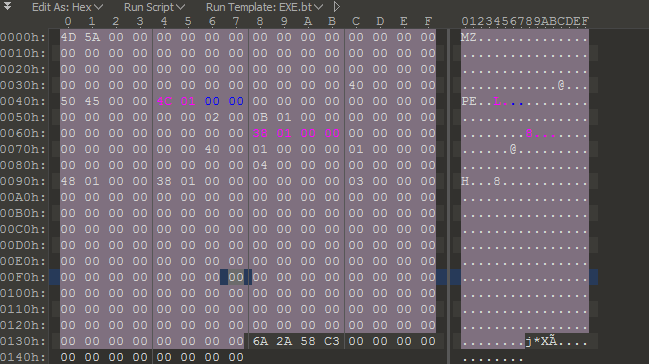
Albertini’s minimal running .exe in hex
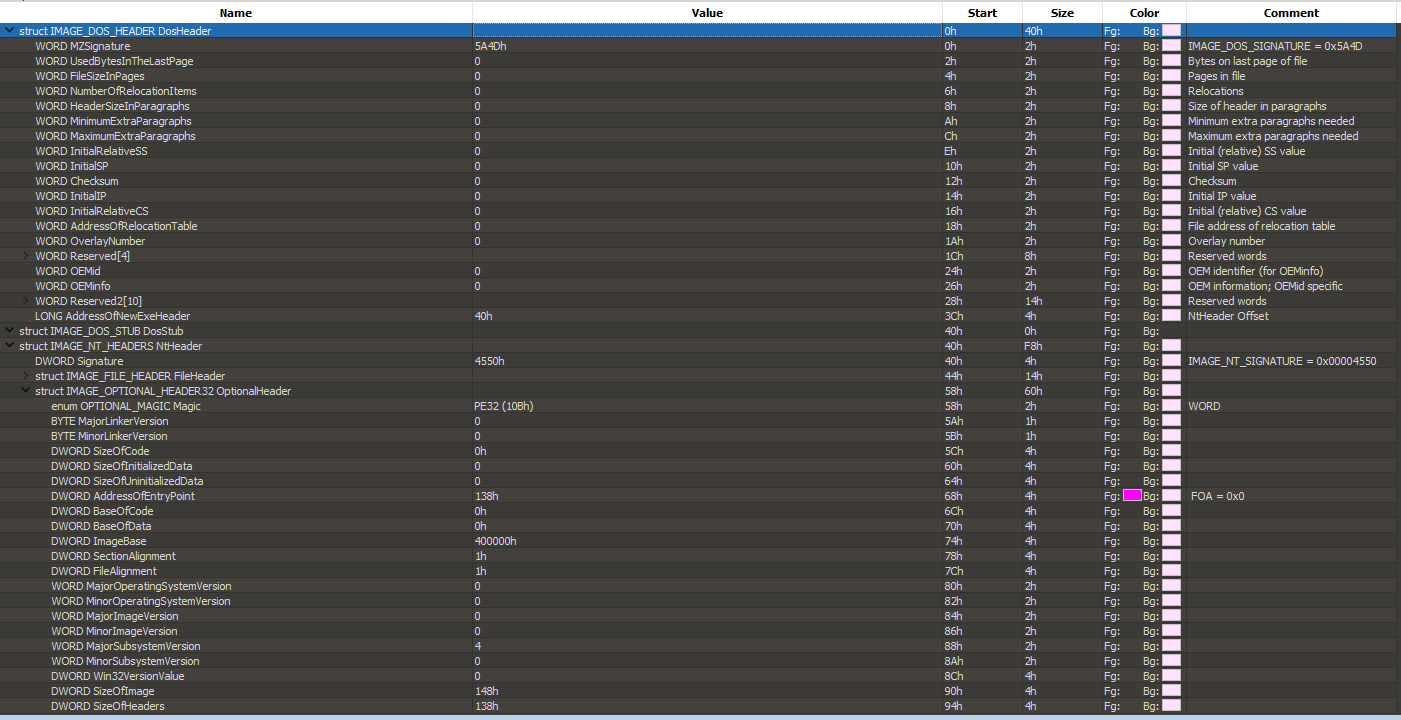
Mini.EXE in Data Structures figure 1
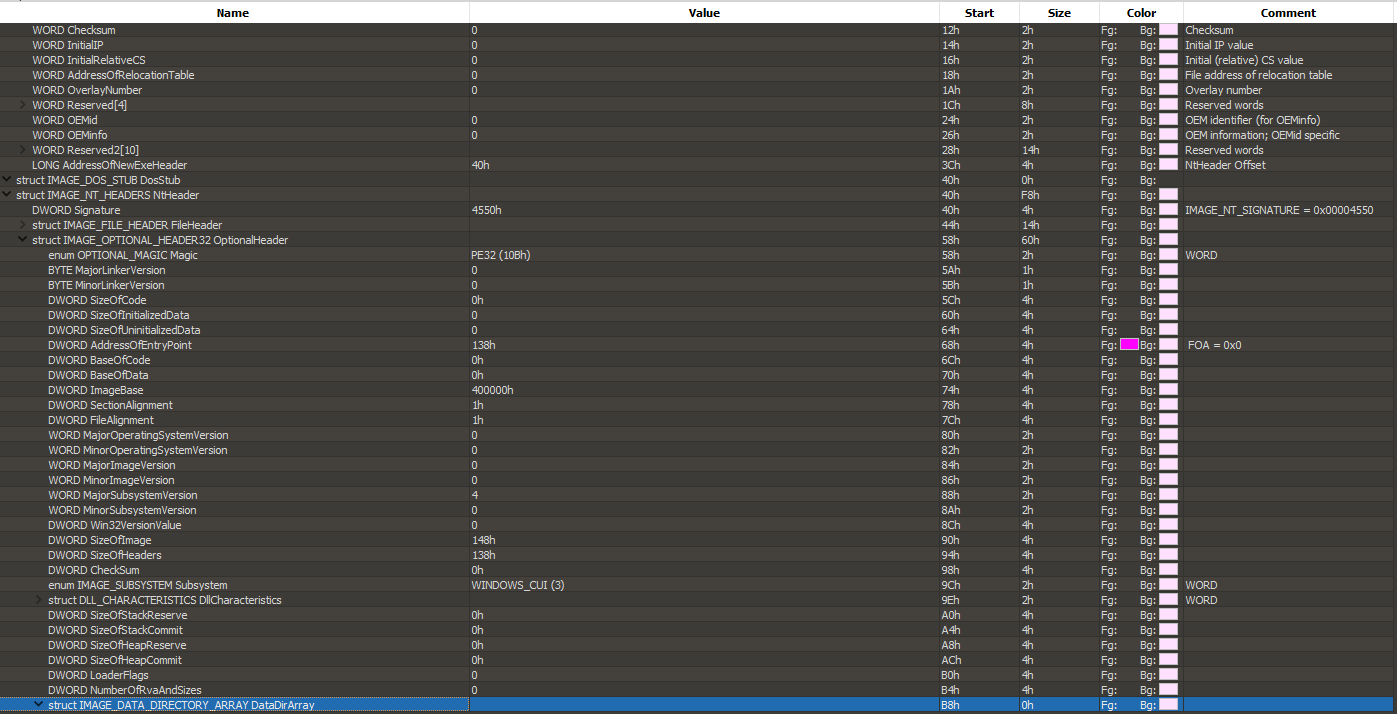
Mini.EXE in Data Structures 2
This means that the Loader enforces some constraints:
- The MZ Header must be present as discussed earlier
- e_lfanew, the address of then PE Signature must also be present.
- The DOS Stub is not required
- The NtHeader is required, along with the PE Signature hex bytes 45 50
- The FileHeader is required because the Machine member is needed, to specify which type of architecture this file is for
- The OptionalHeader is required for its Magic, AddressOfEntryPoint, ImageBase, SectionAlignment, FileAlignment, MajorSubsystemVersion, SizeOfImage, SizeOfHeaders, and Subsytem members
What do we learn from this? A couple of things:
- The OptionalHeader is absolutely not optional. For if it were, it would not be in this executable.
- The OptionalHeader is also the most important structure as it holds the majority of the required elements for the PE file to execute.
- The least bit of information the loader needs to work include the signatures, where to map the file, how much space the file will take up in memory, and the operating system version
Thus, when a file will not start, these should be the first pieces of data that we examine. It’s possible that something else is causing the loader to fail, but more than likely, invalid values in one of these areas is the culprit. Let’s look at a few case studies:
Case Study #1 – Invalid Win32 Application
The error
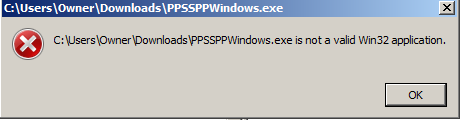
In this example, we’re using Windows 7 64 bit. Already, we know that this is not an issue of running a 64 bit file on a 32 bit machine. In fact, Windows is telling us that this is not a valid Win32 application at all. Okay… Why not? Let’s take a look.
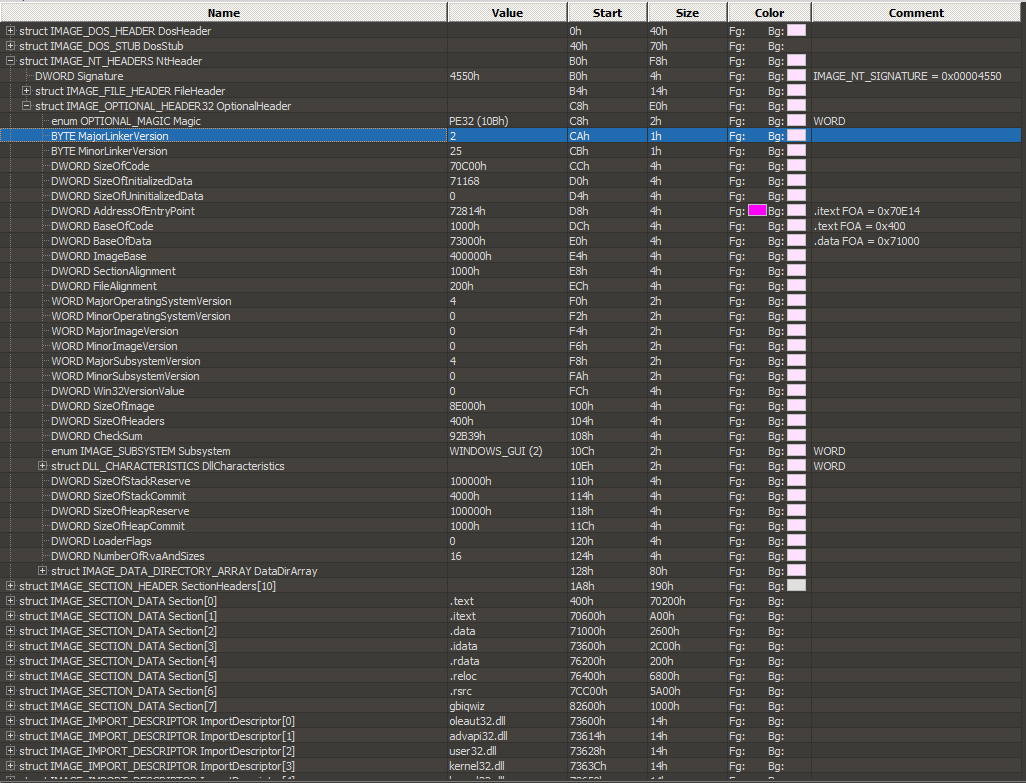
File looks good from birds eye view
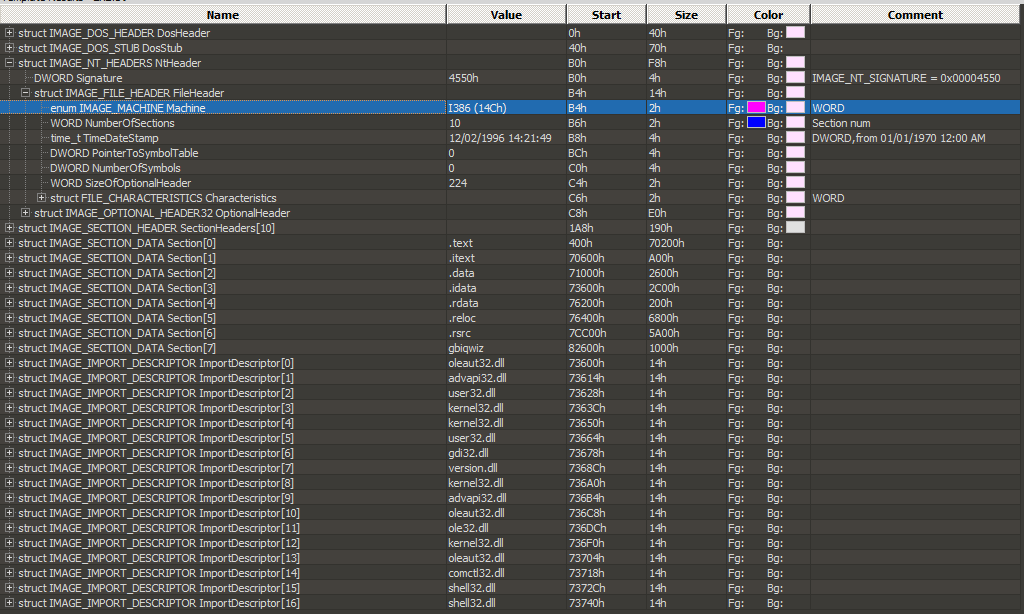
We have sections, imports, and even Machine.
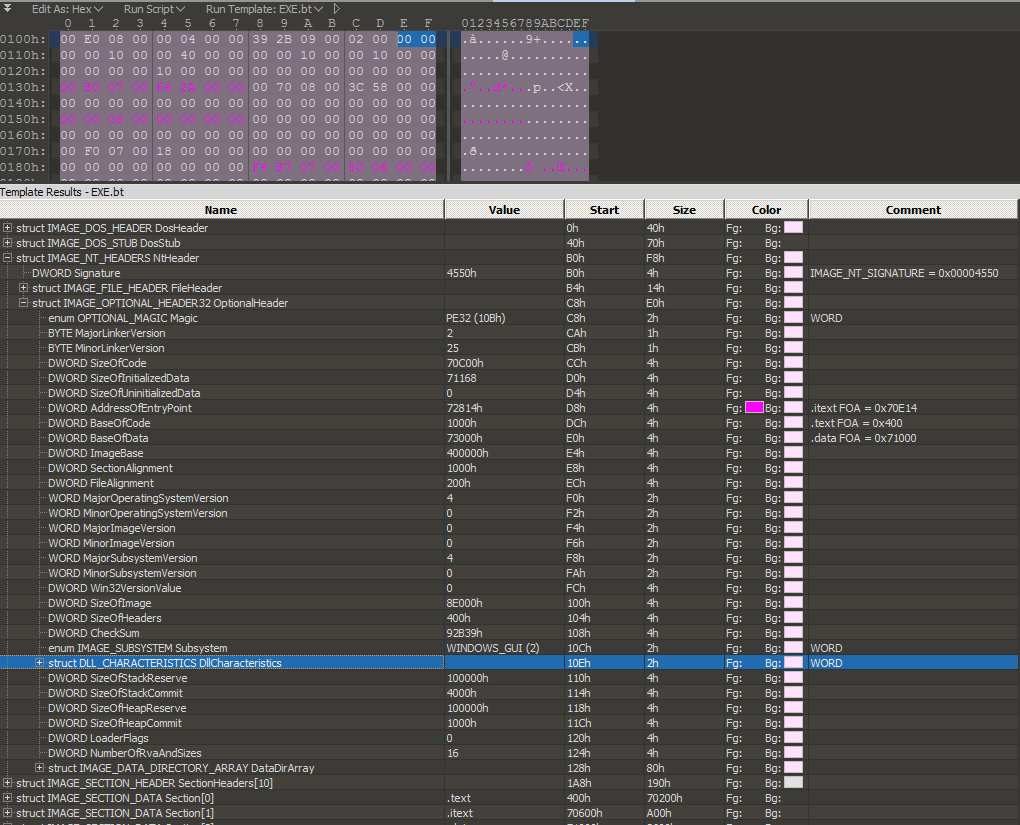
The OptionalHeader is intact, complete with ImageBase, SectionAlignment, FileAlignment, StartAddress, Subsystem, SizeOfImage, SizeOfHeaders
So what’s the problem??? Wait, let’s have a closer look at the operating system version:
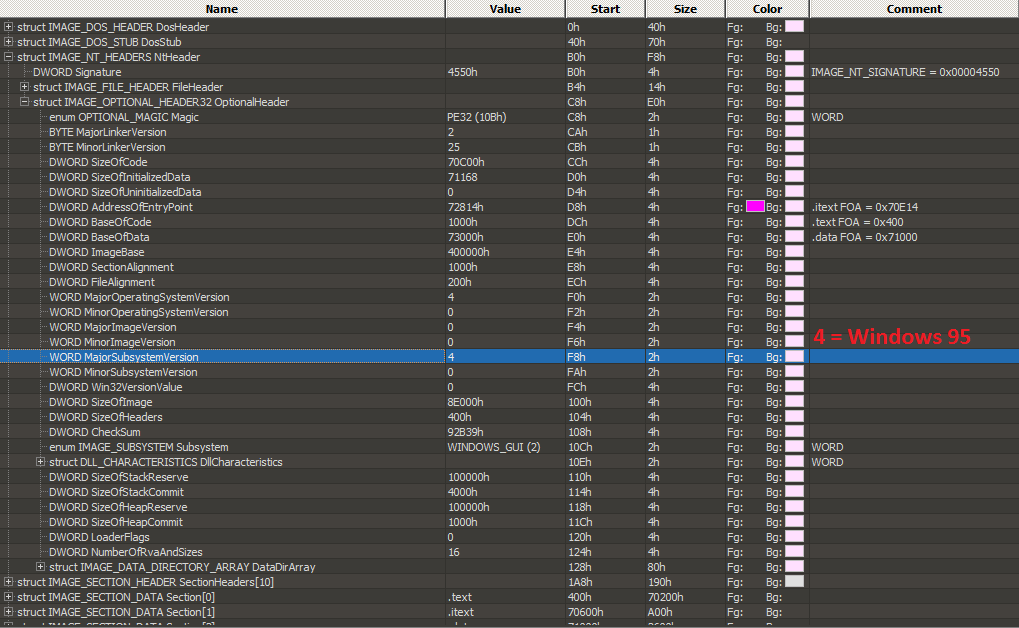
Now, let’s examine the AddressOfEntryPoint, relative to the boundaries of the code:
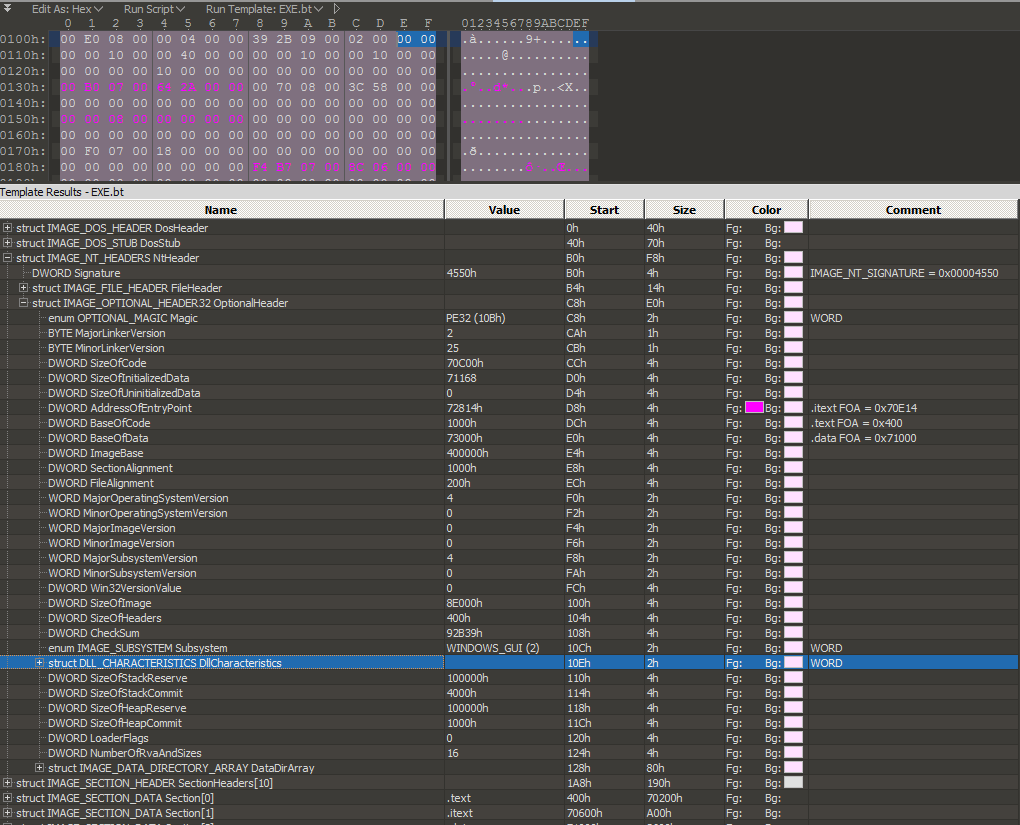
The BaseOfCode, SizeOfCode, and AddressOfEntryPoint do not add up.
It appears that the AddressOfEntryPoint is outside of the code area because the BaseOfCode is at 1000h, SizeOfCode is 70C00h, and AddressOfEntryPoint is at 72814h which is past 71C00h by C14 or decimal 3,092 bytes. However, this is not necessarily the case, according to Albertini whose research demonstrates that actually, BaseOfCode and SizeOfCode are not even necessary and are of little importance to the Image Loader. This is where the PE format itself lead me into a dead-end.
Away from the Format and Into the Loader
In order to answer this question, I’ve now moved on to studying the Windows Loader modules themselves, especially as implemented in NtCreateSection and associated routines. Essentially, NtCreateSection gets called, and internally, it uses functions which validate the integrity of the PE file because of course in order to utilize the PE data structures, it must first make sure that they are valid. So far, I’ve used three sources to examine this process up-close and although I don’t have an answer to this question of why the file will not load just yet, I’ve made some serious progress toward that answer.
The biggest hardship to getting the answer about why the file would not load comes from the fact that the image loader never actually starts because the kernel does some pre-validation before the proper loader is even handed the file. The file apparently has been failing this pre-validation step and the process is never even created. This has presented several challenges:
- Since the file will not load at all, there is no process ID or handle to grab onto for debugging purposes
- The error, as shown above, is very generic and gives no particular reason as to why the file won’t load.
- It has been a challenge to isolate the problem since the relevant kernel routines are being called so often that it is too obtuse to just throw a generic breakpoint on NtCreateSection for example. NtCreateSection is being called at all times by many different processes.
So what’s next? I asked this question: “What is our caller?” And the answer is, in the case of double-clicking the file, Explorer.exe is. In fact, in ProcMon, when we attempt to run the file, we can see Explorer.exe running the operation “CreateFileMapping.” Well, turns out, CreateFileMapping is using NtCreateSection at the start to try and load the file. In order to get this figured out, I had no choice but to use WinDbg (Wind Bag) and go into kernel-mode debugging. This was a real beast because I was unable to get WinDbg to cooperate (pipe) to my VirtualBox lab VM no matter what I did. I watched every single tutorial video on this, read about 5 articles, and for whatever reason, the pipe would not connect between WinDbg and my VirtualBox setup. Eventually, I was told about VirtualKD, a program which is supposed to act as a catalyst for Windows kernel debugging via virtual machine and it works especially well with VMWare. I exported my VirtualBox lab VM to an OVA, then imported that OVA into VMWare and finally, using VirtualKD was able to get the WinDbg kernel debugging going. This process took nearly 15 days of on/off work in my spare time. If you are having issues with this, drop a comment or post on https://malwareanalysisforums.com and I’ll do my best to help you out.
Closure At Last
I remembered the Windows Research Kernel and took a look on Github for NtCreateSection. I opened “Base” followed by “ntoskrnl” because I was aware that the routines I was looking for at this point were bottom-level kernel routines. In this folder, I saw a file called “creasect.c” and in a crapshoot attempt, opened it up. I was presented with a comment stated that this was the implementation of NtCreateSection. Score!
I simultaneously also went into reactOS’s source code ntoskrnl virtual memory manager (mm for short) because I was given a tip on this several months ago when I was doing research for a similar project.
The goal in the above endeavors was to study the PE image loading process to learn about how validation checks are done, in an attempt to better understand what could cause a file to refuse to load and give the generic “Invalid Win32 Application” error. This mission was accomplished because what I discovered was that most of these checks indeed are part of the memory management modules of the Windows kernel, rather than the actual Loader modules, which are prefixed with Ldr. My initial assumption was that the Ldr modules were what I was looking for but this was not correct. In fact, by the time the Loader modules are operating on the file, it is already fully loaded into memory and they are used more for the relocation and symbol resolution phases as well as throughout the usage of the application continually.
Additionally, it’s clear that reactOS’s NtCreateSection has stricter checks on the PE header than the one implemented in the Windows Research Kernel. I also want to take this time to note that the Research Kernel doesn’t necessarily reflect the latest version of Windows. I believe it was taken from either Server 2003 or Windows XP so it is dated and there are probably some newer checks happening that we can’t see the source for. Lastly, I went through every single PE Header check in the creasect.c file and wrote it down then cross-referenced the entire case-study file’s PE header to make sure there were no issues. I found none.
The main “loading from disk to memory” occurs in NtCreateSection, which is responsible for validating the structural integrity of the PE file, setting up the sections, ensuring proper segmentation alignment, and more. But for our purposes, this is all we need out of NtCreateSection. After reading through the source code for some time, I discovered this chain of events:
- NtCreateSection is basically a wrapper which calls the heavy-lifting function MmCreateSection.
- MmCreateSection does many things to set up the mapping from disk to memory, but one of the things that it does is call MiCreateFileMap.
- MiCreateFileMap is the big boy that does all of the work we are interested in. It is the largest function in the file. MiCreateFileMap performs many checks on the PE file’s integrity. This routine’s checks mainly have to do with the section, segment, and page alignment of the actual data to be mapped rather than the PE Header.
- MiCreateFileMap calls MiVerifyImageHeader, which is another function that handles most of the PE Header integrity checks, many of which are documented by Albertini in his PE file research. However, at least in this older implementation which is given to us as the Research Kernel, the number of header checks is noticeably lacking compared to the PE/COFF specification, as noted by Albertini’s findings.
To conclude, there are probably around 50 checks which happen just in this creasect.c file which are used to verify the PE file’s integrity. If any of these checks fail, the file will not load. The code returned by the memory mapping modules in nearly every case is STATUS_INVALID_IMAGE_FORMAT or to the CPU, 0xC000007B. This is all of the detail that this kernel module exposes to its consumers, but having a look through the source code gives ideas of specifically what can cause a PE file to not load. For starters, there are 38 occurrences which can return a STATUS_INVALID_IMAGE_FORMAT and several others which cause an indirect return of the same. Here are three examples of checks which can invalidate the PE file from creasect.c of the Windows Research Kernel. The first two are section alignment checks inside of MiCreateFileMap. The last shot is of a large validation block within MiVerifyImageHeader:
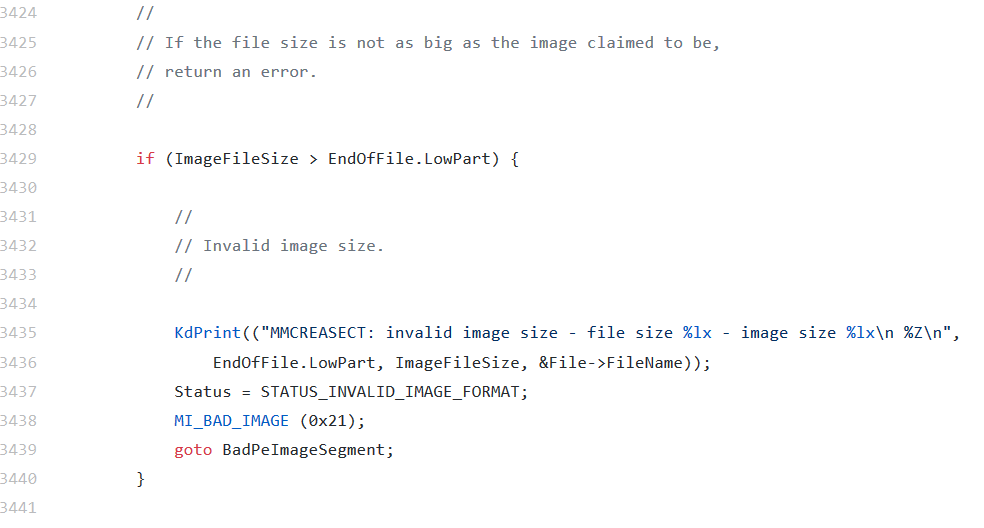
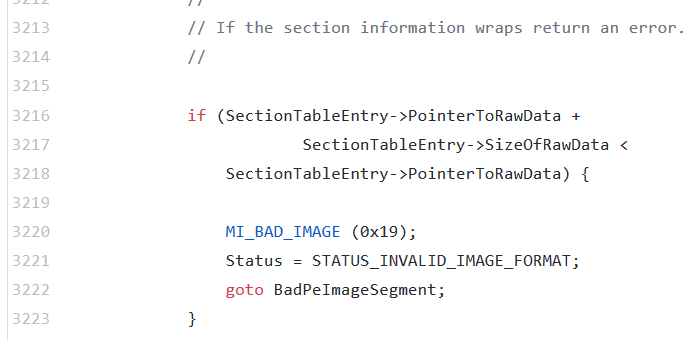

I’d like to point out that there are also these error codes which are present and will cause a PE to be rejected by the OS as well: STATUS_INVALID_IMAGE_WIN_16, STATUS_INVALID_IMAGE_PROTECT, STATUS_INVALID_IMAGE_NOT_MZ, STATUS_INVALID_IMAGE_LE_FORMAT. However, we won’t be examining the triggers for these errors in this article as they are for other formats that we are not studying. If you are interested, just go to creasect.c and search for those terms.
WinDbg
Now that I had narrowed down the logic we were looking for to just MiCreateFileMap and MiVerifyImageHeader, it was much easier to try and verify the cause via WinDbg for our case study file specifically. I opened up WinDbg and my analysis VM. I then opened up an admin cmd.exe and navigated to the folder with the case study file. Finally, I launched the file to make sure everything was ready to go and sure enough, received the “Invalid Win32 Application” error again.
I now went to Debug -> Break in WinDbg and entered the following commands:
bp nt!MiCreateFileMap
bp nt!MiVerifyImageHeader
It is possible to first use the command !process 0 0 to get a list of process memory addresses, then take the address of explorer.exe and put it in the breakpoint command like bp /p fffff800`028c6a45 nt!NtCreateSection which will only break when NtCreateSection is called by explorer.exe in this example. However, I did not do this because the frequency that these two functions above were being called by other processes was not enough to warrant that, since no other processes were loading PEs at this time.
I stepped through these routines and what I found was that MiCreateFileMap called MiVeryImageHeader just as we mentioned earlier, and when MiVerifyImageHeader returned, it returned with code 0 which is SUCCESS. This means that the only chance the PE image would not load here was going to be found inside of MiCreateFileMap. Sure enough, I entered the command pt which tells WinDbg to “step to next return.” At this point, I was looking at the ret for MiCreateFileMap… The moment of truth. Lastly, I entered r rax and sure enough, inside RAX’s low 32 bits was 0xC000007B for invalid PE:

STATUS_INVALID_IMAGE_FORMAT found being returned from MiCreateImageFileMap
Lessons Learned
- WinDbg is a very powerful tool and worth the hassle of setting up and learning. In fact, technically, WinDbg can make a malware analyst nearly unstoppable in finding malware since it can externally control the entire OS and step through everything that occurs on it.
- Windows uses lots and lots of interfaces and wrapper functions
- The PE validation and integrity checks are not actually part of “the image loader” (Ldr funcs) but instead, the memory management routines of the kernel and frankly, the implementation of all of this was deeper into the virtual memory manager and more closely related to the section alignment stuff than I had anticipated; though in hindsight, this makes a lot of sense.
- As suspected, there are indeed many causes of the “Invalid Win32 Application error” but nearly all (especially in regards to initial file load) can be viewed in the NtCreateSection implementation
- There are other factors aside from the header entirely which can “corrupt” or otherwise cause a PE to error out with that message, especially factors involving section, segment, and page alignment.
- The data regarding the “sections” of the file is the most sensitive and likely to cause this generic invalid Win32 application error. This means that throwing off the section headers OR the bytes in a section is a quick and easy way to create this error. An example that will not generally create this error is throwing off the import descriptors. I literally opened up the IAT and threw random garbage values into it on a repeated basis, and the only error created was “unable to locate xyz.dll” rather than “Not a valid Win32 Application.” However, if I threw random garbage bytes into a section directly, especially the .reloc one, OR threw off SizeofRawData/PointerToRawData in the section header, the error was created. This is consistent with what we’ve seen in the actual implementation of NtCreateSection. The largest chunk of code involves validating the actual sections and producing an STATUS_INVALID_PE_FORMAT | STATUS_INVALID_IMAGE_PROTECT error if they fail the series of checks.
- To reinforce the above point, all it takes is a wrong number in a section header or some stray bytes that throw off the section/segment alignment to trigger the error.
Suggested Reading/Help, I’m lost!
The below resources are excellent and will also help if you were confused by any of the above content:
- Page Tables – Wikipedia
- Virtual Memory – Wikipedia
- WinDbg Commands – WinDbg.info
- Corkami’s PE Research – GitHub
- ntoskrnl.exe (Func prefix definitions) – Wikipedia
Special Thanks
I just wanted to leave a special thanks to Corkami for all of his extensive research on the PE format as well as Igor Skochinsky for heading me in the initial direction of NtCreateSection as an avenue to investigate the loading issue.